Explain
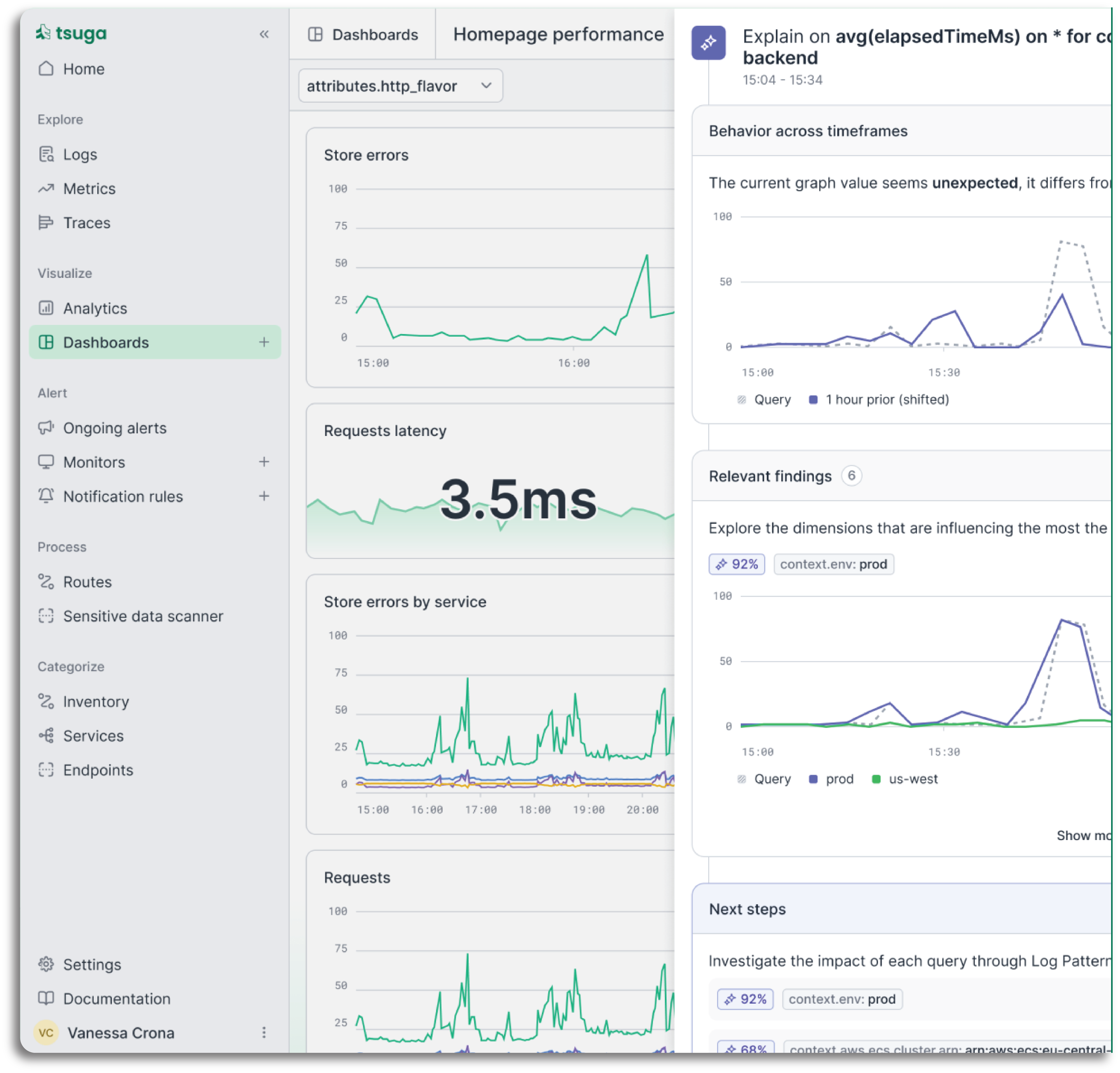
Most incident investigations start with the same question: what changed? Engineers open dashboards, filter by time window, compare service after service, and try to isolate which dimension is responsible for the spike. In large distributed systems with dozens of services and hundreds of metrics, that manual process can easily take 20 minutes before anyone has even formed a hypothesis.
Tsuga AI's Explain capability does that work automatically. The moment a spike or anomaly appears, it observes the relevant dimensions across your entire telemetry estate, identifies the signals that changed at the same time, and surfaces a plain-language explanation alongside the relevant log and trace context. No dashboard-hopping. No manual correlation. Just the answer, ready when your team needs it.
- Scans hundreds of dimensions to find what changed at the moment of the spike
- Identifies the smallest subset of signals that explains the behaviour
- Surfaces a clear explanation alongside the relevant log and trace context
- Suggests where to look next, so investigation has direction from the start